













Q*
The maker of ChatGPT had made progress on Q* (pronounced Q-Star), which some internally believe could be a breakthrough in the startup's search for superintelligence, also known as artificial general intelligence (AGI).

Q-Star: OpenAI's Exploration of Q-Learning in Pursuit of Artificial General Intelligence (AGI)

This article is based on a Reuters news article from 2023-11-22 titled OpenAI Researchers Warned Board of AI Breakthrough Ahead of CEO Ouster
Q-learning, a cornerstone in artificial intelligence, is integral to reinforcement learning. This model-free algorithm aims to discern the value of actions within specific states, striving to establish an optimal policy that maximizes rewards over time.
Fundamentals of Q-Learning
At its core, Q-learning hinges on the Q-function, or state-action value function. This function evaluates the expected total reward from a given state and action, following the optimal policy.
The Q-Table: A key feature in simpler Q-learning applications is the Q-table. Each state is represented by a row, and each action by a column. The Q-values, reflecting the state-action pairs, are continually updated as the agent learns from its environment.
The Update Rule: Q-learning's essence is encapsulated in its update formula:
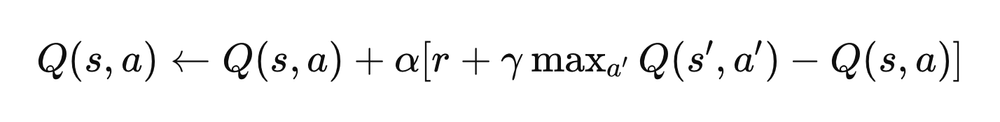
\[ Q(s,a) \leftarrow Q(s,a) + \alpha [r + \gamma \max_{a'} Q(s', a') - Q(s, a)] \]
This equation incorporates the learning rate (α), discount factor (γ), reward (r), current state (s), current action (a), and new state (s′).
Exploration vs. Exploitation: Balancing new experiences and utilizing known information is crucial. Strategies like the ε-greedy method manage this balance by alternating between exploration and exploitation based on a set probability.
Q-Learning's Role in Advancing AGI
AGI encompasses an AI's capability to broadly apply its intelligence, similar to human cognitive abilities. While Q-learning is a step in this direction, it faces several hurdles:
Scalability: Q-learning's applicability to large state-action spaces is limited, a critical issue for AGI's diverse problem-solving needs.
Generalization: AGI requires extrapolating from learned experiences to new situations, a challenge for Q-learning which generally needs specific training for each scenario.
Adaptability: AGI's dynamic adaptability to evolving environments is at odds with Q-learning's need for stable environments.
Integration of Cognitive Skills: AGI involves a blend of various skills, including reasoning and problem-solving, beyond Q-learning's learning-focused approach.
Progress and Future Outlook
Deep Q-Networks (DQN): Merging Q-learning with deep neural networks, DQNs are better suited for complex tasks due to their ability to handle high-dimensional spaces.
Transfer Learning: Techniques allowing Q-learning models to apply knowledge across different domains hint at the generalization required for AGI.
Meta-Learning: Integrating meta-learning into Q-learning could enable AI to refine its learning strategies, a key component for AGI.
In its quest for AGI, OpenAI's focus on Q-learning within Reinforcement Learning from Human Feedback (RLHF) is a noteworthy endeavor.









