













What is OCR Technology and How Does it Work?
Learn how Optical Character Recognition (OCR) technology transforms images into editable text. This article breaks down the OCR process into pre-processing, feature extraction, and post-processing, providing insights into its applications and how it works.


OCR stands for Optical Character Recognition. It means for the computer to detect and extract editable, updatable, and storable text from images.
Today, OCR is used in many web applications and day-to-day tasks. Some examples can be barcode scanning at a supermarket, or firms digitizing their physical documents for easy cloud storage.
However, not many people know the definition or the real working mechanism behind OCR. They see it around them, but the what, how, and why unimaginably bewilder their minds.
That’s why we came up with this post to help you learn about OCR – what it does and how it works.
Working Mechanism Behind OCR
We can divide the working mechanism of OCR into three steps.
These are: A) Pre-processing, B) Feature Extraction, and C) Post-Processing.
Below, we’ll talk about each one of them in detail.
Pre-Processing
This is the first step an OCR software takes when it first receives an image. It analyzes the picture in various manners, checking for mainly the following things:
- Clarity
- Orientation
- Completeness
By clarity, we mean that the OCR tool checks how clear the text is in the image. On many occasions, images get blurry due to improper lighting conditions which causes loss of data in the conversion process.
Orientation means the horizontal or vertical alignment of the image (or digital document) with the center. The OCR tool ensures that the input file is upright without any distortions for the text.
Finally, the intelligent software makes sure that the user has uploaded a complete file to it. Many times, we tend to hurry up our work and submit inappropriately cropped images. This leads to serious truncation of data and loss of information.
So, the application takes all the precautionary steps it can to inform the user about the condition of the input. If there must be an error after the process, it must be detected before any resources are wasted.
Feature Extraction
This step is the heart of OCR. This is where the tool starts picking up characters from the image. It does so by looking for a gradient in brightness and contrast between the text and the image’s background.
The written text is mostly darker than the background, so the OCR tool accurately copies words from the image for the user.
For example, look below at the four different images presented for your liking.
See, the top row of images has a distinguishable text, even to the human eye. This is because there’s a visible difference between the colors of the text and the background of the image.
However, as we move down to the bottom row, we can see that it’s getting slightly tough to differentiate the text from the background. Especially in the bottom-right corner image.
Thus, feeding such an image with low contrast between the text and image would ultimately confuse the tool during feature extraction. Consequently, it might come up with inconsistent results, or recognize words in a wrong manner.
Post-Processing
The final step that OCR technology-equipped tools take to work is post-processing. This means analyzing the copied text from the image and checking if the extracted characters make sense.
The tool does so by comparing the words with a built-in dictionary that works similarly to a normal one you can find online or physically.
Let’s take an example from an online OCR tool to understand how it works. The software utilizes advanced Machine Learning algorithms to copy text from images in a matter of seconds.

Then, the tools tally words with the dictionaries to display results for the user. Let’s extract text from the above image using an online OCR tool to verify that it is working.
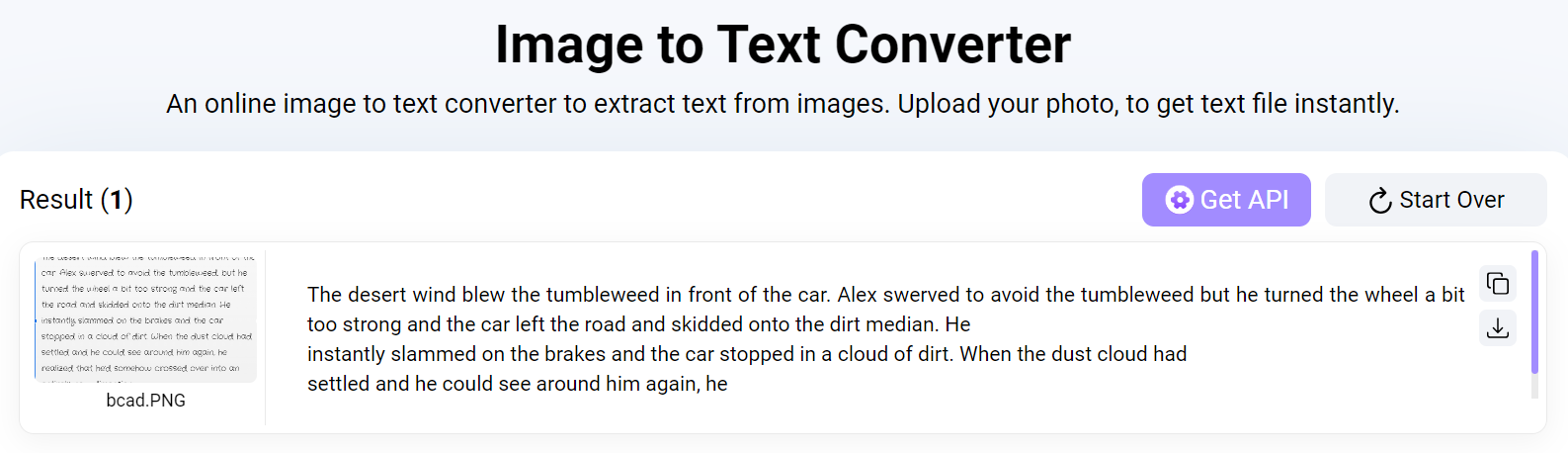
Sure enough, the tool quickly and accurately copied all the text from the image and presented it to us. Now, we can download the result as a .doc, or .txt file. Or, salvage the text to our clipboard.
The final functionality of an OCR tool is to utilize the extracted text elsewhere with some internal processes like:
- Translators (if another language)
- Talking to web servers (for uploading the data directly without user interference.)
- Sending the data to other departments (if the tool is implemented in an organization.)
Organizational OCRs are mostly integrated with such internal tools. So, they send their extracted textual data to the other part of the system, hence ending the working mechanism of an OCR tool.
Final Words
In this post, we learned the complete secret behind OCR technology and how it works. We saw that the tools start with preparing the image for extraction by canceling out any orientation, completion, or clarity issues.
Then, the OCR tools extract the characters based on the gradient of pixel-brightness value between the text and image background. Finally, the tools recognize the extracted textual material with their built-in language datasets to approve the data as accurate.
That’s it for the post! We hope you enjoyed reading our content!









