













University of Oxford study identifies when AI hallucinations are more likely to occur
A University of Oxford study developed a means of testing when language models are “unsure” of their output or hallucinating. AI “hallucinations” refer to a phenomenon where large language models (LLMs) generate fluent and plausible responses that are not grounded in truth or consistent across conversations. In other words, an LLM is said to be hallucinating when it produces content that appears convincing on the surface but is fabricated or inconsistent with previous statements. Hallucinations are tough – if not impossible – to separate from AI models. AI developers like OpenAI, Google, and Anthropic have all admitted that hallucinations will The post University of Oxford study identifies when AI hallucinations are more likely to occur appeared first on DailyAI.

A University of Oxford study developed a means of testing when language models are “unsure” of their output or hallucinating.
AI “hallucinations” refer to a phenomenon where large language models (LLMs) generate fluent and plausible responses that are not grounded in truth or consistent across conversations.
In other words, an LLM is said to be hallucinating when it produces content that appears convincing on the surface but is fabricated or inconsistent with previous statements.
Hallucinations are tough – if not impossible – to separate from AI models. AI developers like OpenAI, Google, and Anthropic have all admitted that hallucinations will likely remain a byproduct of interacting with AI.
As Dr. Sebastian Farquhar, one of the study’s authors, explains in a blog post, “LLMs are highly capable of saying the same thing in many different ways, which can make it difficult to tell when they are certain about an answer and when they are literally just making something up.”
The Cambridge Dictionary even added an AI-related definition to the word in 2023 and named it “Word of the Year.”
The question this University of Oxford study sought to answer is: what’s really going on under the hood when an LLM hallucinates? And how can we detect when it’s likely to happen?
The researchers aimed to address the problem of hallucinations by developing a novel method to detect exactly when an LLM is likely to generate fabricated or inconsistent information.
The study, published in Nature, introduces a concept called “semantic entropy,” which measures the uncertainty of an LLM’s output at the level of meaning rather than just the specific words or phrases used.
By computing the semantic entropy of an LLM’s responses, the researchers can estimate the model’s confidence in its outputs and identify instances when it’s likely to hallucinate.
Identifying exactly when a model is likely to hallucinate enables the preemptive detection of those hallucinations.
In high-stakes applications like finance or law, such detection would enable users to shut down the model or probe its responses for accuracy before using them in the real world.
Semantic entropy in LLMs
Semantic entropy, as defined by the study, measures the uncertainty or inconsistency in the meaning of an LLM’s responses. It helps detect when an LLM might be hallucinating or generating unreliable information.
Here’s how it works:
- The researchers actively prompted the LLM to generate several possible responses to the same question. This is achieved by feeding the question to the LLM multiple times, each time with a different random seed or slight variation in the input.
- Semantic entropy examines responses and groups those with the same underlying meaning, even if they use different words or phrasing.
- If the LLM is confident about the answer, its responses should have similar meanings, resulting in a low semantic entropy score. This suggests that the LLM clearly and consistently understands the information.
- However, if the LLM is uncertain or confused, its responses will have a wider variety of meanings, some of which might be inconsistent or unrelated to the question. This results in a high semantic entropy score, indicating that the LLM may hallucinate or generate unreliable information.
To evaluate semantic entropy’s effectiveness, the researchers applied it to a diverse set of question-answering tasks.
This involved benchmarks like trivia questions, reading comprehension, word problems, and biographies.
Across the board, semantic entropy outperformed existing methods for detecting when an LLM was likely to generate an incorrect or inconsistent answer.
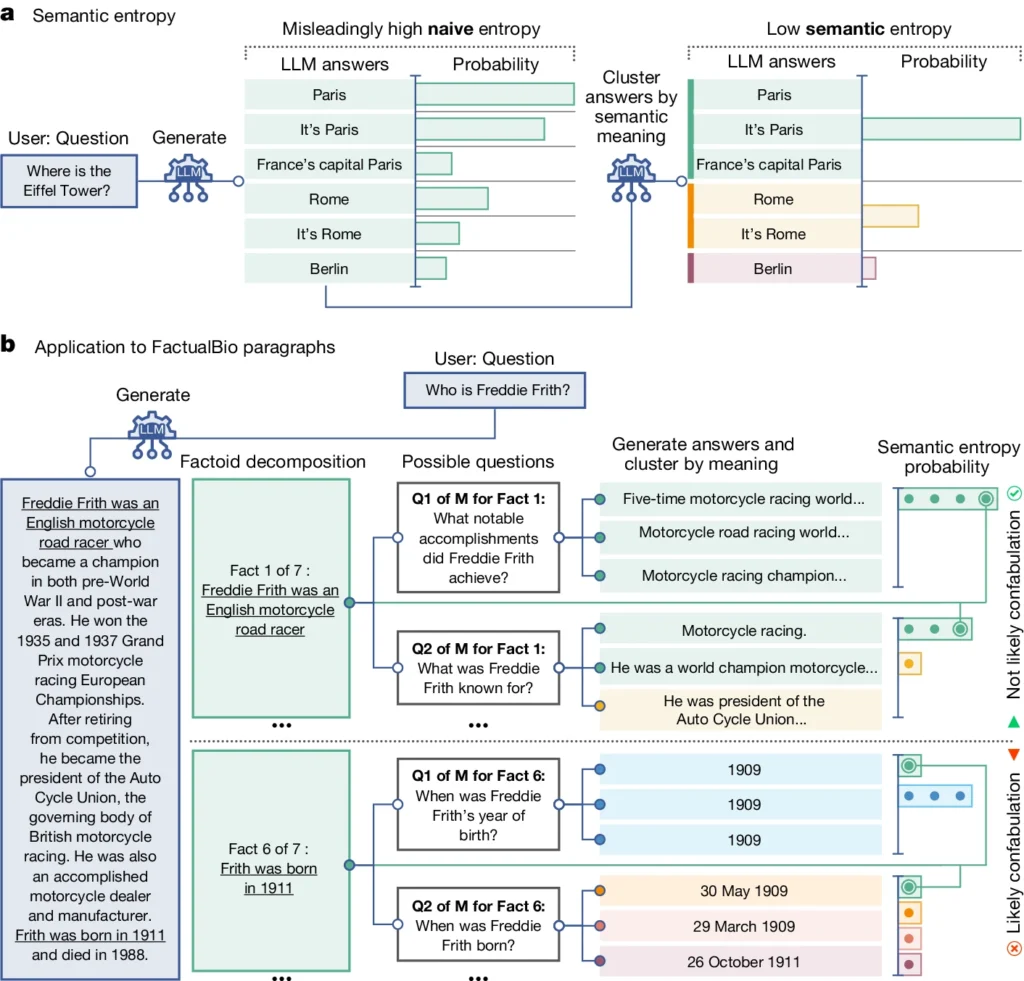
In simpler terms, semantic entropy measures how “confused” an LLM’s output is.
You can see in the above diagram how some prompts push the LLM to generate a confabulated (inaccurate) response, such as it produces a day and month of birth when this wasn’t provided in the initial information.
The LLM will likely provide reliable information if the meanings are closely related and consistent. But if the meanings are scattered and inconsistent, it’s a red flag that the LLM might be hallucinating or generating inaccurate information.
By calculating the semantic entropy of an LLM’s responses, researchers can detect when the model will likely produce unreliable or inconsistent information, even if the generated text seems fluent and plausible on the surface.
Implications
This work can help explain hallucinations and make LLMs more reliable and trustworthy.
By providing a way to detect when an LLM is uncertain or prone to hallucination, semantic entropy paves the way for deploying these AI tools in high-stakes domains where factual accuracy is critical, like healthcare, law, and finance.
Erroneous results can potentially have catastrophic impacts in these areas, as shown by some failed predictive policing and healthcare systems.
However, it’s important to remember that hallucination is just one type of error that LLMs can make.
As Dr. Farquhar notes, “If an LLM makes consistent mistakes, this new method won’t catch that. The most dangerous failures of AI come when a system does something bad but is confident and systematic. There is still a lot of work to do.”
Nevertheless, the Oxford team’s semantic entropy method represents a major step forward in our ability to understand and mitigate the limitations of AI language models.
Providing an objective means to detect them brings us closer to a future where we can harness AI’s potential while ensuring it remains a reliable and trustworthy tool in the service of humanity.
The post University of Oxford study identifies when AI hallucinations are more likely to occur appeared first on DailyAI.









