













Transforming Imagery with AI: Exploring Generative Models and the Segment Anything Model (SAM)
Generative models have redefined what’s possible in computer vision, enabling innovations once only imaginable in science fiction. One breakthrough tool is the Segment Anything Model (SAM), which has dramatically simplified isolating subjects in images. In this blog, we’ll explore an application leveraging SAM and text-to-image diffusion models to give users unprecedented control over digital environments. Through SAM’s ability to manipulate imagery paired with diffusion models’ capacity to generate scenes from text, this app allows transforming images in groundbreaking ways.Project OverviewThe goal is to build a web app that allows a user to upload an image, use SAM to create a segmentation mask highlighting the main subject, and then use Stable Diffusion inpainting to generate a new background based on a text prompt. The result is a seamlessly modified image that aligns with the user’s vision.How It WorksImage Upload and Subject Selection: Users start by uploading an image and selecting the main object they wish to isolate. This selection triggers SAM to generate a precise mask around the object.Mask Refinement: SAM’s initial mask can be refined by the user, adding or removing points to ensure accuracy. This interactive step ensures that the final mask perfectly captures the subject.Background or Subject Modification: Once the mask is finalized, users can specify a new background or a different subject through a text prompt. An infill model processes this prompt to generate the desired changes, integrating them into the original image to produce a new, modified version.Final Touches: Users have the option to further tweak the result, ensuring the modified image meets their expectations.Implementation and ModelI used SAM (Segment Anything Model) from Meta to handle the segmentation. This model can create high-quality masks with just a couple of clicks to mark the object's location.Stable Diffusion uses diffusion models that add noise to real images over multiple steps until they become random noise. A neural network is then trained to remove the noise and recover the original images. By reversing this denoising process on random noise, the model can generate new realistic images matching patterns in the training data.SAM (Segment Anything Model) generates masks of objects in an image without requiring large supervised datasets. With only a couple clicks to indicate the location of an object, it can accurately separate the “subject” from the “background”, which is useful for compositing and manipulation tasks.Stable Diffusion generates images from text prompts and inputs. The inpainting mode allows part of an image to be filled in or altered based on a text prompt.Combining SAM with diffusion techniques, I set out to create an application that empowers users to reimagine their photos, whether by swapping backgrounds, changing subjects, or creatively altering image compositions.Loading the model and processing the imagesHere, we import the necessary libraries and load the SAM model.Image Segmentation with SAM (Segment Anaything Model)Using SAM, we segment the selected subject from the image.Inpainting with Diffusion ModelsI utilize the inpainting model to alter the background or subject based on user prompts.The inpainting model takes three key inputs: the original image, the mask-defining areas to edit, and the user’s textual prompt. The magic happens in how the model can understand and artistically interpret these prompts to generate new image elements that blend seamlessly with the untouched parts of the photo.Interactive appTo allow easy use of the powerful Stable Diffusion model for image generation, an interactive web application using Gradio can be built. Gradio is an open-source Python library that enables quickly converting machine learning models into demos and apps, perfect for deploying AI like Stable Diffusion.ResultsThe backgrounds were surprisingly coherent and realistic, thanks to Stable Diffusion’s strong image generation capabilities. There’s definitely room to improve the segmentation and blending, but overall, it worked well.Future steps to exploreThey are improving image and video quality while converting from text to image. Many startups are working on improving the video quality after prompting the text for various use cases.Transforming Imagery with AI: Exploring Generative Models and the Segment Anything Model (SAM) was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Generative models have redefined what’s possible in computer vision, enabling innovations once only imaginable in science fiction. One breakthrough tool is the Segment Anything Model (SAM), which has dramatically simplified isolating subjects in images. In this blog, we’ll explore an application leveraging SAM and text-to-image diffusion models to give users unprecedented control over digital environments. Through SAM’s ability to manipulate imagery paired with diffusion models’ capacity to generate scenes from text, this app allows transforming images in groundbreaking ways.
Project Overview
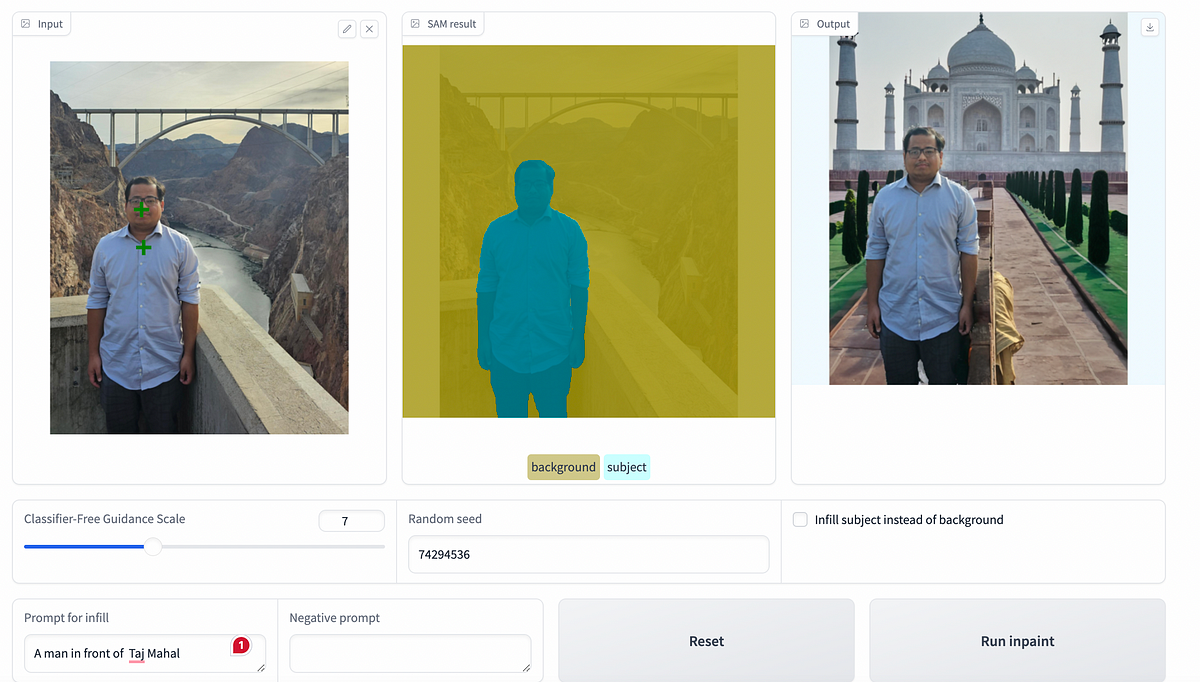
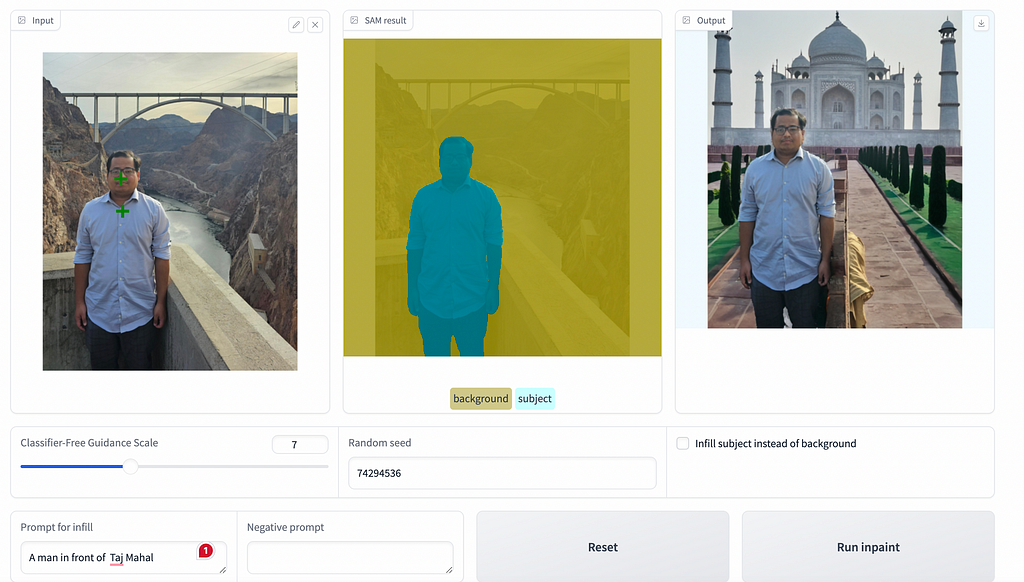
The goal is to build a web app that allows a user to upload an image, use SAM to create a segmentation mask highlighting the main subject, and then use Stable Diffusion inpainting to generate a new background based on a text prompt. The result is a seamlessly modified image that aligns with the user’s vision.
How It Works
- Image Upload and Subject Selection: Users start by uploading an image and selecting the main object they wish to isolate. This selection triggers SAM to generate a precise mask around the object.
- Mask Refinement: SAM’s initial mask can be refined by the user, adding or removing points to ensure accuracy. This interactive step ensures that the final mask perfectly captures the subject.
- Background or Subject Modification: Once the mask is finalized, users can specify a new background or a different subject through a text prompt. An infill model processes this prompt to generate the desired changes, integrating them into the original image to produce a new, modified version.
- Final Touches: Users have the option to further tweak the result, ensuring the modified image meets their expectations.
Implementation and Model
I used SAM (Segment Anything Model) from Meta to handle the segmentation. This model can create high-quality masks with just a couple of clicks to mark the object's location.
Stable Diffusion uses diffusion models that add noise to real images over multiple steps until they become random noise. A neural network is then trained to remove the noise and recover the original images. By reversing this denoising process on random noise, the model can generate new realistic images matching patterns in the training data.
SAM (Segment Anything Model) generates masks of objects in an image without requiring large supervised datasets. With only a couple clicks to indicate the location of an object, it can accurately separate the “subject” from the “background”, which is useful for compositing and manipulation tasks.
Stable Diffusion generates images from text prompts and inputs. The inpainting mode allows part of an image to be filled in or altered based on a text prompt.
Combining SAM with diffusion techniques, I set out to create an application that empowers users to reimagine their photos, whether by swapping backgrounds, changing subjects, or creatively altering image compositions.
Loading the model and processing the images


Here, we import the necessary libraries and load the SAM model.
Image Segmentation with SAM (Segment Anaything Model)
Using SAM, we segment the selected subject from the image.

Inpainting with Diffusion Models
I utilize the inpainting model to alter the background or subject based on user prompts.

The inpainting model takes three key inputs: the original image, the mask-defining areas to edit, and the user’s textual prompt. The magic happens in how the model can understand and artistically interpret these prompts to generate new image elements that blend seamlessly with the untouched parts of the photo.
Interactive app
To allow easy use of the powerful Stable Diffusion model for image generation, an interactive web application using Gradio can be built. Gradio is an open-source Python library that enables quickly converting machine learning models into demos and apps, perfect for deploying AI like Stable Diffusion.
Results
The backgrounds were surprisingly coherent and realistic, thanks to Stable Diffusion’s strong image generation capabilities. There’s definitely room to improve the segmentation and blending, but overall, it worked well.
Future steps to explore
They are improving image and video quality while converting from text to image. Many startups are working on improving the video quality after prompting the text for various use cases.
Transforming Imagery with AI: Exploring Generative Models and the Segment Anything Model (SAM) was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.









