













Just Say "No": How AI Politeness Drives up Costs
There is a Dollar cost to Token Outputs. Which means when training your Company's AI - there is a fine line between polite and cost efficient.


As artificial intelligence becomes increasingly integrated into various business operations, the cost of running these systems is coming under greater scrutiny. Large Language Models (LLMs) like GPT-3 and GPT-4, while powerful, are expensive to develop, maintain, and deploy. The energy consumption and token costs associated with these models can quickly add up, especially when AI responses are designed to be overly polite or verbose. Currently, many AI systems are fine-tuned to operate at a politeness level of 50 to 60%, which ensures user satisfaction but also contributes to higher costs (Ribino, 2023).
This raises an important question: Can businesses reduce these costs by fine-tuning AI responses to be more direct, and therefore, more efficient?
The Expensive Reality of Building AI
Developing LLMs from scratch is a resource-intensive process, often requiring millions of dollars and vast computational power. As a result, many companies opt to build their AI tools on existing infrastructures, such as those provided by OpenAI or other major players.
This strategy, while cost-effective, means that the inherent characteristics and limitations of these models are also inherited, including their token usage and energy consumption profiles (ScienceDirect, 2023).
For instance platforms like CopyAI and Jasper, which rely on the GPT-4 API, are essentially fine-tuned versions of an existing model. This reliance allows for rapid deployment and reduces the need for extensive development resources. However, the downside is that the fine-tuned models also carry forward any inefficiencies embedded in the original architecture. According to DevPro Journal (2024), the operational costs tied to token usage are a significant concern, particularly for companies seeking to maximize efficiency.
What does this mean? One of the most straightforward methods for cost reduction lies in fine-tuning the output instructions of these models. By adjusting the "politeness index" and opting for more direct responses, companies can reduce the number of tokens required per interaction. As an example, lets tell an AI a wrong statement.
Reducing Politeness to Cut Energy Costs

In Christopher Nolan’s Interstellar, Cooper adjusts the settings of the robot TARS, fine-tuning its honesty and humor levels. This parallels the real-world need for companies to optimize their AI systems for efficiency. Specifically, fine-tuning the politeness of AI responses can significantly impact token usage and, as a result, energy consumption.
Politeness in AI responses often leads to longer and more complex sentences, which, while enhancing user experience, also increase the number of tokens used. Consider the following example:
"Humans have 203 bones in their body"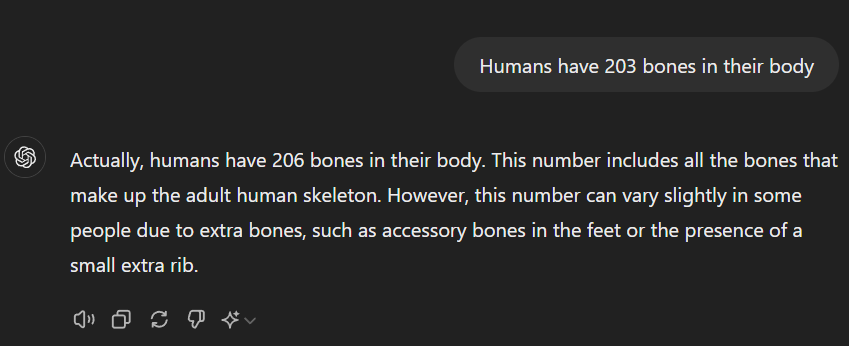
OpenAI has a Tokenizer counter, which you can upload text to see how many tokens the response would be. The polite response from above is 56 tokens. A more direct response though, is 15 tokens. The Token Counter results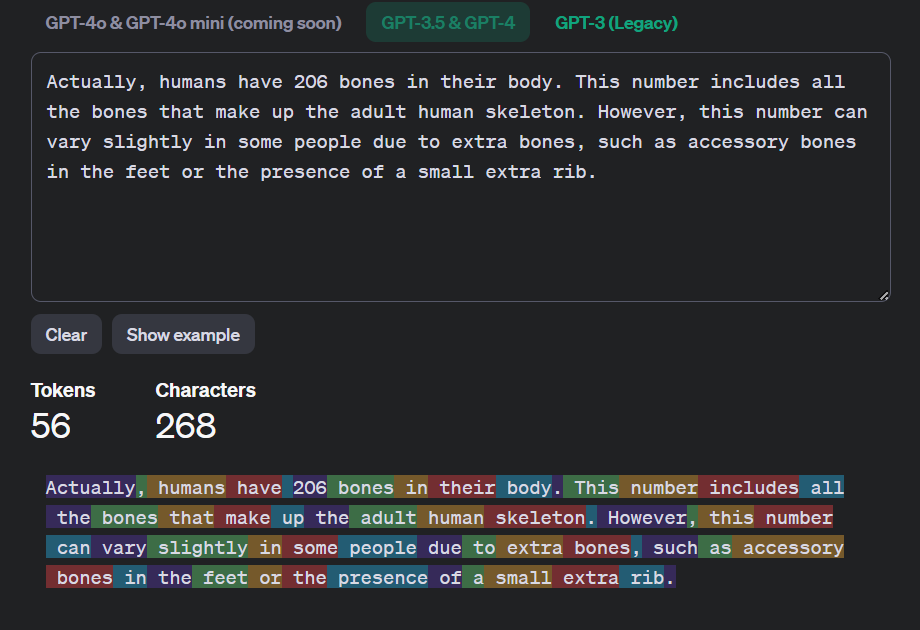
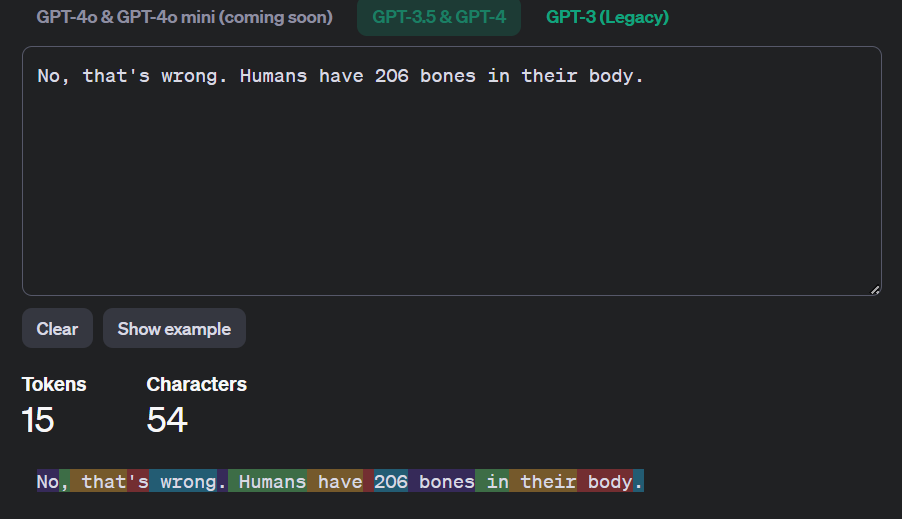
The polite response uses nearly four times as many tokens as the blunt response. This increased token usage directly translates to higher energy consumption. Research has shown that energy consumption per token is a significant factor in the overall cost of running LLMs, with estimates suggesting that each token might consume around 0.047 kWh for 1,000 inferences (Luccioni, Jernite, & Strubell, 2024; ScienceDirect, 2023). When scaled across millions of interactions daily, this difference can result in substantial energy savings.
While polite AI interactions are generally preferred in public-facing applications due to their positive impact on user satisfaction and trust, the energy and cost savings of a blunter approach should not be overlooked in more controlled settings (DevPro Journal, 2024). For instance, with companies that are forcing their employees to use the internal AI tools for work instead of insecure public LLMs, then there isn't as much of a concern for adoption.
Fine-tuning the politeness level of the models in closed-source AI tools will reduce operational costs. Similar to Cooper with TARS, by reducing the token count per response - it translates to a lower operational cost.
Is it a $3.77 billion yearly difference for OpenAI?
For this, we'll be looking at the cost based on assumptions from publicly existing data.
For OpenAI's ChatGPT, there is around 100 million weekly users. The average queries per user per day is around 15. Energy cost per token is roughly .047 kWh for text generation for 1,000 inferences. Average tokens per query is around 2k tokens. Dollar Cost per token is $.0000047 when cost per kWh is $.10.
Say that 100 million users are using ChatGPT weekly. That's 1.5 billion queries per day. With 2k tokens per query average, that's 3 trillion tokens.
TARS, 30% politeness please.
In Conclusion
As companies continue to integrate AI into their operations, the cost implications of token usage and energy consumption become increasingly significant. While developing LLMs from scratch remains an option for those with substantial resources, most businesses will find it more feasible to build and optimize on existing infrastructures. By directly tuning the output though, for businesses relying on existing APIs for their closed off LLMs, that might be one of the biggest cost savers.
Ultimately, the future of AI lies in balancing efficiency with user experience, and fine-tuning models for specific use cases will be a crucial strategy in achieving this balance. As the demand for AI continues to grow, so too will the need for cost-effective, energy-efficient solutions that can deliver value without unnecessary expenditure, without needing to rely on future cost-cutting AI advances. After all, the cost is now.
References
- DevPro Journal. (2024, June 17). The secret ingredient for successful AI? Politeness. DevPro Journal. Retrieved from https://www.devprojournal.com/technology-trends/ai/the-secret-ingredient-for-successful-ai-politeness/
- Luccioni, S., Jernite, Y., & Strubell, E. (2024, June). Power hungry processing: Watts driving the cost of AI deployment? The 2024 ACM Conference on Fairness, Accountability, and Transparency. https://doi.org/10.1145/3630106.3658542
- ScienceDirect. (2023, April 1). Trends in AI inference energy consumption: Beyond the performance-vs-parameter laws of deep learning. ScienceDirect. Retrieved from https://www.sciencedirect.com/science/article/pii/S2210537923000124
- The Verge. (2024, February 16). How much electricity does AI consume? The Verge. Retrieved from https://www.theverge.com/24066646/ai-electricity-energy-watts-generative-consumption
- Ribino, P. (2023, June 27). The role of politeness in human–machine interactions: A systematic literature review and future perspectives. ACM Computing Surveys. Retrieved from https://dl.acm.org/doi/10.1007/s10462-023-10540-1
- PubMed. (2023, November 30). Should robots be polite? Expectations about politeness in human–robot language-based interaction. PubMed. Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10720661/
- Forbes. (2024, May 18). Hard evidence that please and thank you in prompt engineering counts when using generative AI. Forbes. Retrieved from https://www.forbes.com/sites/lanceeliot/2024/05/18/hard-evidence-that-please-and-thank-you-in-prompt-engineering-counts-when-using-generative-ai/
- Frontiers in Robotics and AI. (2023). Should robots be polite? Expectations about politeness in human–robot language-based interaction. Frontiers in Robotics and AI. Retrieved from https://www.frontiersin.org/journals/robotics-and-ai/articles/10.3389/frobt.2023.1242127/full
- arXiv. (2024, July 25). Computational politeness in natural language processing: A survey. arXiv. Retrieved from https://arxiv.org/html/2407.12814v1
- SpringerLink. (2023, June 27). The role of politeness in human–machine interactions. SpringerLink. Retrieved from https://link.springer.com/article/10.1007/s10462-023-10540-1
- HackerNoon. (2024, July 2). Manners matter? - The impact of politeness on human-LLM interaction. HackerNoon. Retrieved from https://hackernoon.com/manners-matter-the-impact-of-politeness-on-human-llm-interaction







