













The rise of “opensource” AI models: transparency and accountability in question
As the era of generative AI marches on, a broad range of companies have joined the fray, and the models themselves have become increasingly diverse. Amidst this AI boom, many companies have touted their models as “open source,” but what does this really mean in practice? The concept of open source has its roots in the software development community. Traditional open-source software makes the source code freely available for anyone to view, modify, and distribute. In essence, open-source is a collaborative knowledge-sharing device fueled by software innovation, which has led to developments like the Linux operating system, Firefox web browser, The post The rise of “opensource” AI models: transparency and accountability in question appeared first on DailyAI.

As the era of generative AI marches on, a broad range of companies have joined the fray, and the models themselves have become increasingly diverse.
Amidst this AI boom, many companies have touted their models as “open source,” but what does this really mean in practice?
The concept of open source has its roots in the software development community. Traditional open-source software makes the source code freely available for anyone to view, modify, and distribute.
In essence, open-source is a collaborative knowledge-sharing device fueled by software innovation, which has led to developments like the Linux operating system, Firefox web browser, and Python programming language.
However, applying the open-source ethos to today’s massive AI models is far from straightforward.
These systems are often trained on vast datasets containing terabytes or petabytes of data, using complex neural network architectures with billions of parameters.
The computing resources required cost millions of dollars, the talent is scarce, and intellectual property is often well-guarded.
We can observe this in OpenAI, which, as its namesake suggests, used to be an AI research lab largely dedicated to the open research ethos.
However, that ethos quickly eroded once the company smelled the money and needed to attract investment to fuel its goals.
Why? Because open-source products are not geared towards profit, and AI is expensive and valuable.
However, as generative AI has exploded, companies like Mistral, Meta, BLOOM, and xAI are releasing open-source models to further research while preventing companies like Microsoft and Google from hoarding too much influence.
But how many of these models are truly open-source in nature, and not just by name?
Clarifying how open open-source models really are
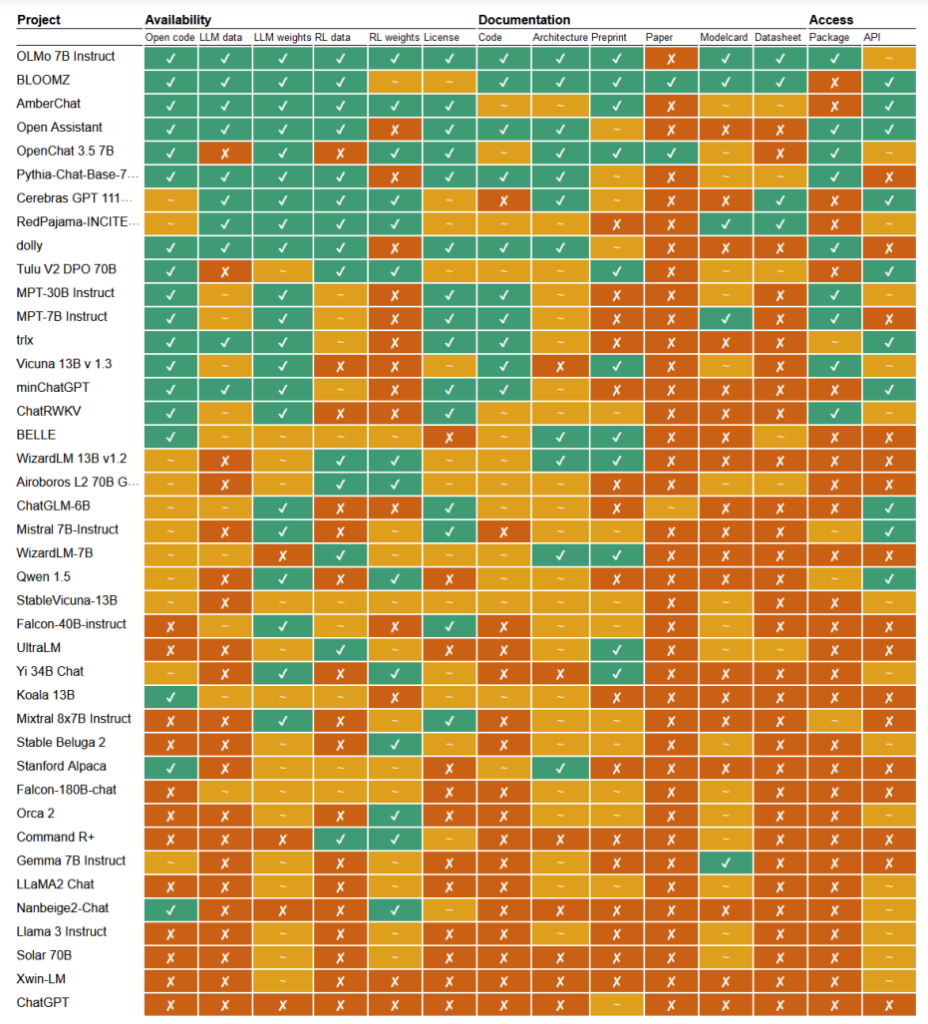
In a recent study, researchers Mark Dingemanse and Andreas Liesenfeld from Radboud University, Netherlands, analyzed numerous prominent AI models to explore how open they are. They studied multiple criteria, such as the availability of source code, training data, model weights, research papers, and APIs.
For example, Meta’s LLaMA model and Google’s Gemma were found to be simply “open weight,” – meaning the trained model is publicly released for use without full transparency into its code, training process, data, and fine-tuning methods.
On the other end of the spectrum, the researchers highlighted BLOOM, a large multilingual model developed by a collaboration of over 1,000 researchers worldwide, as an exemplar of true open-source AI. Every element of the model is freely accessible for inspection and further research.
The paper assessed some 30+ models (both text and image), but these demonstrate the immense variation within those that claim to be open-source:
- BloomZ (BigScience): Fully open across all criteria, including code, training data, model weights, research papers, and API. Highlighted as an exemplar of truly open-source AI.
- OLMo (Allen Institute for AI): Open code, training data, weights, and research papers. API only partially open.
- Mistral 7B-Instruct (Mistral AI): Open model weights and API. Code and research papers only partially open. Training data unavailable.
- Orca 2 (Microsoft): Partially open model weights and research papers. Code, training data, and API closed.
- Gemma 7B instruct (Google): Partially open code and weights. Training data, research papers, and API closed. Described as “open” by Google rather than “open source”.
- Llama 3 Instruct (Meta): Partially open weights. Code, training data, research papers, and API closed. An example of an “open weight” model without fuller transparency.
A lack of transparency
The lack of transparency surrounding AI models, especially those developed by large tech companies, raises serious concerns about accountability and oversight.
Without full access to the model’s code, training data, and other key components, it becomes extremely challenging to understand how these models work and make decisions. This makes it difficult to identify and address potential biases, errors, or misuse of copyrighted material.
Copyright infringement in AI training data is a prime example of the problems that arise from this lack of transparency. Many proprietary AI models, such as GPT-3.5/4/40/Claude 3/Gemini, are likely trained on copyrighted material.
However, since training data is kept under lock and key, identifying specific data within this material is nearly impossible.
The New York Times’s recent lawsuit against OpenAI demonstrates the real-world consequences of this challenge. OpenAI accused the NYT of using prompt engineering attacks to expose training data and coax ChatGPT into reproducing its articles verbatim, thus proving that OpenAI’s training data contains copyright material.
“The Times paid someone to hack OpenAI‘s products,” stated OpenAI.
In response, Ian Crosby, the lead legal counsel for the NYT, said, “What OpenAI bizarrely mischaracterizes as ‘hacking’ is simply using OpenAI’s products to look for evidence that they stole and reproduced The Times’ copyrighted works. And that is exactly what we found.”
Indeed, that’s just one example from a huge stack of lawsuits that are currently roadblocked partly due to AI models’ opaque, impenetrable nature.
This is just the tip of the iceberg. Without robust transparency and accountability measures, we risk a future where unexplainable AI systems make decisions that profoundly impact our lives, economy, and society yet remain shielded from scrutiny.
Calls for openness
There have been calls for companies like Google and OpenAI to grant access to their models’ inner-workings for the purposes of safety evaluation.
However, the truth is that even AI companies don’t truly understand how their models work.
This is called the “black box” problem, which arises when trying to interpret and explain the model’s specific decisions in a human-understandable way.
For example, a developer might know that a deep learning model is accurate and performs well, but they may struggle to pinpoint exactly which features the model uses to make its decisions.
Anthropic, which developed the Claude models, recently conducted an experiment to identify how Claude 3 Sonnet works, explaining, “We mostly treat AI models as a black box: something goes in and a response comes out, and it’s not clear why the model gave that particular response instead of another. This makes it hard to trust that these models are safe: if we don’t know how they work, how do we know they won’t give harmful, biased, untruthful, or otherwise dangerous responses? How can we trust that they’ll be safe and reliable?”
It’s a pretty remarkable admission, really, that the creator of a technology does not understand its product in the AI era.
This Anthropic experiment illustrated that objectively explaining outputs is an exceptionally tricky task. In fact, Anthropic estimated that it would consume more computing power to ‘open the black box’ than to train the model itself!
Developers are attempting to actively combat the black-box problem through research like “Explainable AI” (XAI), which aims to develop techniques and tools to make AI models more transparent and interpretable.
XAI methods seek to provide insights into the model’s decision-making process, highlight the most influential features, and generate human-readable explanations. XAI has already been applied to models deployed in high-stakes applications such as drug development, where understanding how a model works could be pivotal for safety.
Open-source initiatives are vital to XAI and other research that seeks to penetrate the black box and provide transparency into AI models.
Without access to the model’s code, training data, and other key components, researchers cannot develop and test techniques to explain how AI systems truly work and identify specific data they were trained on.
Regulations might confuse the open-source situation further
The European Union’s recently passed AI Act is set to introduce new regulations for AI systems, with provisions that specifically address open-source models.
Under the Act, open-source general-purpose models up to a certain size will be exempt from extensive transparency requirements.
However, as Dingemanse and Liesenfeld point out in their study, the exact definition of “open source AI” under the AI Act is still unclear and could become a point of contention.
The Act currently defines open source models as those released under a “free and open” license that allows users to modify the model. Still, it does not specify requirements around access to training data or other key components.
This ambiguity leaves room for interpretation and potential lobbying by corporate interests. The researchers warn that refining the open source definition in the AI Act “will probably form a single pressure point that will be targeted by corporate lobbies and big companies.”
There is a risk that without clear, robust criteria for what constitutes truly open-source AI, the regulations could inadvertently create loopholes or incentives for companies to engage in “open-washing” — claiming openness for the legal and public relations benefits while still keeping important aspects of their models proprietary.
Moreover, the global nature of AI development means differing regulations across jurisdictions could further complicate the landscape.
If major AI producers like the United States and China adopt divergent approaches to openness and transparency requirements, this could lead to a fragmented ecosystem in which the degree of openness varies widely depending on where a model originates.
The study authors emphasize the need for regulators to engage closely with the scientific community and other stakeholders to ensure that any open-source provisions in AI legislation are grounded in a deep understanding of the technology and the principles of openness.
As Dingemanse and Liesenfeld conclude in a discussion with Nature, “It’s fair to say the term open source will take on unprecedented legal weight in the countries governed by the EU AI Act.”
How this plays out in practice will have momentous implications for the future direction of AI research and deployment.
The post The rise of “opensource” AI models: transparency and accountability in question appeared first on DailyAI.








