Exploring NLP Preprocessing Techniques: Stopwords, Bag of Words, and Word Cloud
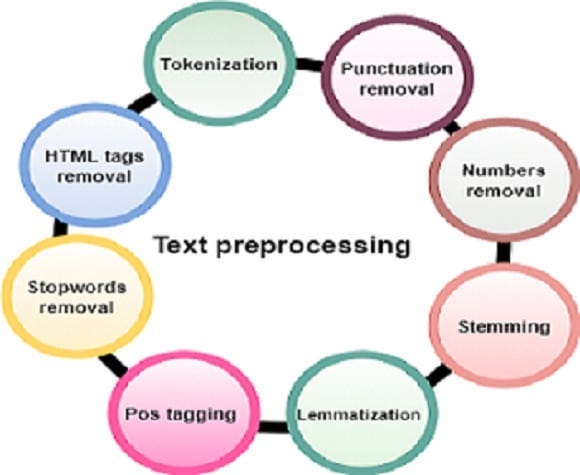
Natural Language Processing (NLP) is a fascinating field that bridges the gap between human communication and machine understanding. One of the fundamental steps in NLP is text preprocessing, which transforms raw text data into a format that can be effectively analyzed and utilized by algorithms. In this blog, we’ll delve into three essential NLP preprocessing techniques: stopwords removal, bag of words, and word cloud generation. We’ll explore what each technique is, why it’s used, and how to implement it using Python. Let’s get started!Stopwords Removal: Filtering Out the NoiseWhat Are Stopwords?Stopwords are common words that carry little meaningful information and are often removed from text data during preprocessing. Examples include “the,” “is,” “in,” “and,” etc. Removing stopwords helps in focusing on the more significant words that contribute to the meaning of the text.Why remove stopwords?Stopwords are removed from:Reduce the dimensionality of the text data.Improve the efficiency and performance of NLP models.Enhance the relevance of features extracted from the text.Pros and ConsPros:Simplifies the text data.Reduces computational complexity.Focuses on meaningful words.Cons:Risk of removing words that may carry context-specific importance.Some NLP tasks may require stopwords for better understanding.ImplementationLet’s see how we can remove stopwords using Python:import nltkfrom nltk.corpus import stopwords# Download the stopwords datasetnltk.download('stopwords')# Sample texttext = "This is a simple example to demonstrate stopword removal in NLP."Load the set of stopwords in Englishstop_words = set(stopwords.words('english'))Tokenize the text into individual wordswords = text.split()Remove stopwords from the textfiltered_text = [word for word in words if word.lower() is not in stop_words]print("Original Text:", text)print("Filtered Text:", " ".join(filtered_text))Code ExplanationImporting Libraries:import nltk from nltk.corpus import stopwordsWe import thenltk library and the stopwords module fromnltk.corpus.Downloading Stopwords:nltk.download('stopwords')This line downloads the stopwords dataset from the NLTK library, which includes a list of common stopwords for multiple languages.Sample Text:text = "This is a simple example to demonstrate stopword removal in NLP."We define a sample text that we want to preprocess by removing stopwords.Loading Stopwords:stop_words = set(stopwords.words('english'))We load the set of English stopwords into the variable stop_words.Tokenizing Text:words = text.split()The split() method tokenizes the text into individual words.Removing Stopwords:filtered_text = [word for word in words if word.lower() is not in stop_words]We use a list comprehension to filter out stopwords from the tokenized words. The lower() method ensures case insensitivity.Printing Results:print("Original Text:", text) print("Filtered Text:", ""). join(filtered_text))Finally, we print the original text and the filtered text after removing stopwords.Bag of Words: Representing Text Data as VectorsWhat Is Bag of Words?The Bag of Words (BoW) model is a technique to represent text data as vectors of word frequencies. Each document is represented as a vector where each dimension corresponds to a unique word in the corpus, and the value indicates the word’s frequency in the document.Why Use Bag of Words?bag of Words is used to:Convert text data into numerical format for machine learning algorithms.Capture the frequency of words, which can be useful for text classification and clustering tasks.Pros and ConsPros:Simple and easy to implement.Effective for many text classification tasks.Cons:Ignores word order and context.Can result in high-dimensional sparse vectors.ImplementationHere’s how to implement the Bag of Words model using Python:from sklearn.feature_extraction.text import CountVectorizer# Sample documentsdocuments = [ 'This is the first document', 'This document is the second document', 'And this is the third document.', 'Is this the first document?']# Initialize CountVectorizervectorizer = CountVectorizer()Fit and transform the documentsX = vectorizer.fit_transform(documents)# Convert the result to an arrayX_array = X.toarray()# Get the feature namesfeature_names = vectorizer.get_feature_names_out()# Print the feature names and the Bag of Words representationprint("Feature Names:", feature_names)print (Bag of Words: \n", X_array)Code ExplanationImporting Libraries:from sklearn.feature_extraction.text import CountVectorizerWe import the CountVectorizer from the sklearn.feature_extraction.text module.Sample Documents:documents = [ 'This is the first document', 'This document is the second document', 'And this is the third document.', 'Is this is the first document?' ]We define a list of sample documents to be processed.Initializing CountVectorizer:vectorizer = CountVectorizer()We create an instance ofCountVectorizer.Fitting and Transforming:X = vectorizer.fit_transform(documents)Thefit_t
Natural Language Processing (NLP) is a fascinating field that bridges the gap between human communication and machine understanding. One of the fundamental steps in NLP is text preprocessing, which transforms raw text data into a format that can be effectively analyzed and utilized by algorithms. In this blog, we’ll delve into three essential NLP preprocessing techniques: stopwords removal, bag of words, and word cloud generation. We’ll explore what each technique is, why it’s used, and how to implement it using Python. Let’s get started!
Stopwords Removal: Filtering Out the Noise
What Are Stopwords?
Stopwords are common words that carry little meaningful information and are often removed from text data during preprocessing. Examples include “the,” “is,” “in,” “and,” etc. Removing stopwords helps in focusing on the more significant words that contribute to the meaning of the text.
Why remove stopwords?
Stopwords are removed from:
- Reduce the dimensionality of the text data.
- Improve the efficiency and performance of NLP models.
- Enhance the relevance of features extracted from the text.
Pros and Cons
Pros:
- Simplifies the text data.
- Reduces computational complexity.
- Focuses on meaningful words.
Cons:
- Risk of removing words that may carry context-specific importance.
- Some NLP tasks may require stopwords for better understanding.
Implementation
Let’s see how we can remove stopwords using Python:
import nltk
from nltk.corpus import stopwords
# Download the stopwords dataset
nltk.download('stopwords')
# Sample text
text = "This is a simple example to demonstrate stopword removal in NLP."
Load the set of stopwords in English
stop_words = set(stopwords.words('english'))
Tokenize the text into individual words
words = text.split()
Remove stopwords from the text
filtered_text = [word for word in words if word.lower() is not in stop_words]
print("Original Text:", text)
print("Filtered Text:", " ".join(filtered_text))Code Explanation
Importing Libraries:
import nltk from nltk.corpus import stopwords
We import thenltk library and the stopwords module fromnltk.corpus.
Downloading Stopwords:
nltk.download('stopwords')This line downloads the stopwords dataset from the NLTK library, which includes a list of common stopwords for multiple languages.
Sample Text:
text = "This is a simple example to demonstrate stopword removal in NLP."
We define a sample text that we want to preprocess by removing stopwords.
Loading Stopwords:
stop_words = set(stopwords.words('english'))
We load the set of English stopwords into the variable stop_words.
Tokenizing Text:
words = text.split()
The split() method tokenizes the text into individual words.
Removing Stopwords:
filtered_text = [word for word in words if word.lower() is not in stop_words]
We use a list comprehension to filter out stopwords from the tokenized words. The lower() method ensures case insensitivity.
Printing Results:
print("Original Text:", text) print("Filtered Text:", ""). join(filtered_text))Finally, we print the original text and the filtered text after removing stopwords.
Bag of Words: Representing Text Data as Vectors
What Is Bag of Words?
The Bag of Words (BoW) model is a technique to represent text data as vectors of word frequencies. Each document is represented as a vector where each dimension corresponds to a unique word in the corpus, and the value indicates the word’s frequency in the document.
Why Use Bag of Words?
bag of Words is used to:
- Convert text data into numerical format for machine learning algorithms.
- Capture the frequency of words, which can be useful for text classification and clustering tasks.
Pros and Cons
Pros:
- Simple and easy to implement.
- Effective for many text classification tasks.
Cons:
- Ignores word order and context.
- Can result in high-dimensional sparse vectors.
Implementation
Here’s how to implement the Bag of Words model using Python:
from sklearn.feature_extraction.text import CountVectorizer
# Sample documents
documents = [
'This is the first document',
'This document is the second document',
'And this is the third document.',
'Is this the first document?'
]
# Initialize CountVectorizer
vectorizer = CountVectorizer()
Fit and transform the documents
X = vectorizer.fit_transform(documents)
# Convert the result to an array
X_array = X.toarray()
# Get the feature names
feature_names = vectorizer.get_feature_names_out()
# Print the feature names and the Bag of Words representation
print("Feature Names:", feature_names)
print (Bag of Words: \n", X_array)
Code Explanation
- Importing Libraries:
from sklearn.feature_extraction.text import CountVectorizer
We import the CountVectorizer from the sklearn.feature_extraction.text module.
Sample Documents:
documents = [ 'This is the first document', 'This document is the second document', 'And this is the third document.', 'Is this is the first document?' ]
We define a list of sample documents to be processed.
Initializing CountVectorizer:
vectorizer = CountVectorizer()
We create an instance ofCountVectorizer.
Fitting and Transforming:
X = vectorizer.fit_transform(documents)
Thefit_transform method is used to fit the model and transform the documents into a bag of words.
Converting to an array:
X_array = X.toarray()
We convert the sparse matrix result to a dense array for easy viewing.
Getting Feature Names:
feature_names = vectorizer.get_feature_names_out()
The get_feature_names_out method retrieves the unique words identified in the corpus.
Printing Results:
print("Feature Names:", feature_names) print("Bag of Words: \n", X_array)
Finally, we print the feature names and the bag of words.
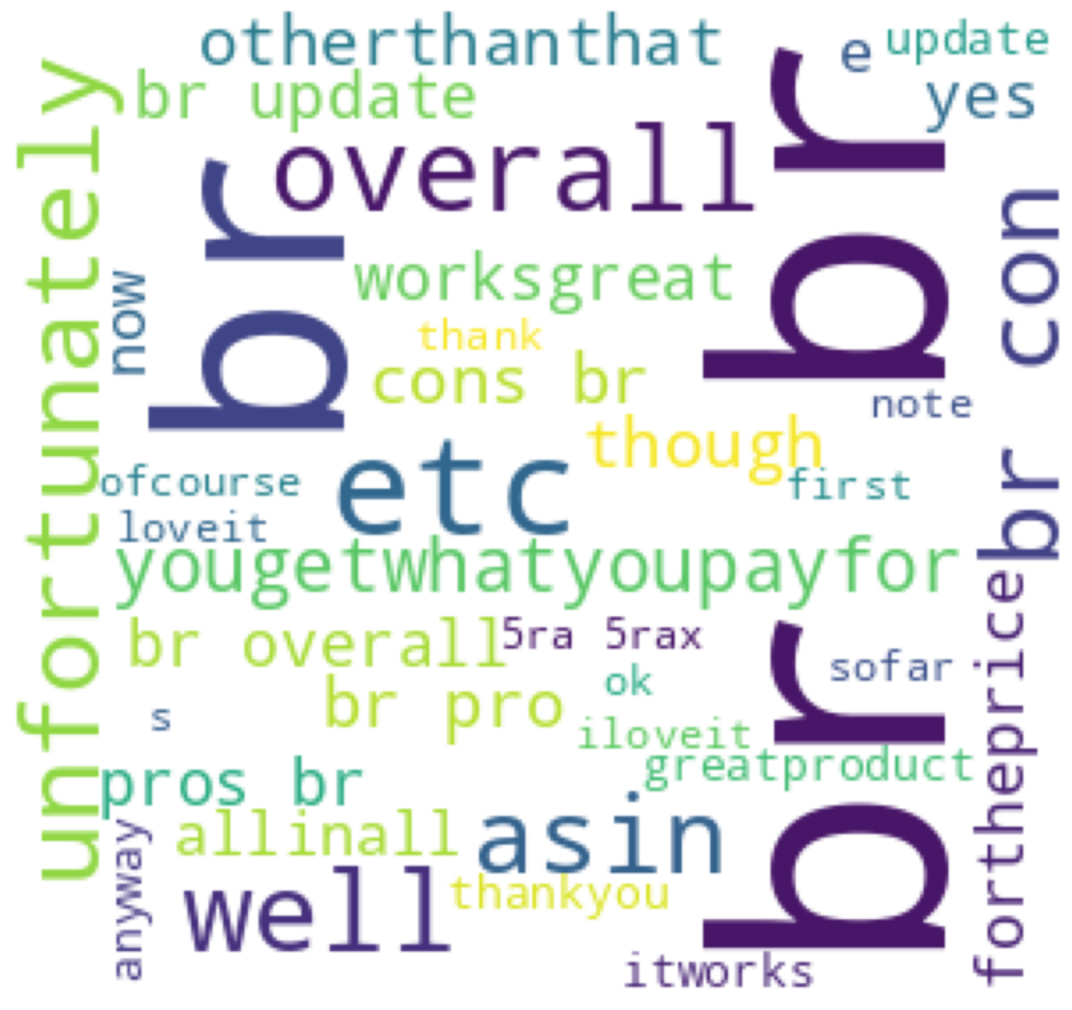
Word Cloud: Visualizing Text Data
What Is a Word Cloud?
A word cloud is a visual representation of text data where the size of each word indicates its frequency or importance. It provides an intuitive and appealing way to understand the most prominent words in a text corpus.
Why Use Word Cloud?
Word clouds are used to:
- Quickly grasp the most frequent terms in a text.
- Visually highlight important keywords.
- Present text data in a more engaging format.
Pros and Cons
Pros:
- Easy to interpret and visually appealing.
- Highlights key terms effectively.
Cons:
- Can oversimplify the text data.
- May not be suitable for detailed analysis.
Implementation
Here’s how to create a word cloud using Python:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# Sample text
df = pd.read_csv('/content/AmazonReview.csv')
comment_words = ""
stopwords = set(STOPWORDS)
for val in df.Review:
val = str(val)
tokens = val.split()
for i in range(len(tokens)):
tokens[i] = tokens[i].lower()
comment_words += "".join(tokens) + ""
pic = np.array(Image.open(requests.get('https://www.clker.com/cliparts/a/c/3/6/11949855611947336549home14.svg.med.png', stream = True).raw))# Generate word clouds
wordcloud = WordCloud(width=800, height=800, background_color='white', mask=pic, min_font_size=12).generate(comment_words)
Display the word cloud
plt.figure(figsize=(8,8), facecolor=None)
plt.imshow(wordcloud)
plt.axis('off')
plt.tight_layout(pad=0)
plt.show()
Code Explanation
- Importing Libraries:
from wordcloud import WordCloud import matplotlib.pyplot as plt
We import the WordCloud class from the wordcloud library and matplotlib.pyplot for displaying the word cloud.
Generating Word Clouds:
wordcloud = WordCloud(width=800, height=800, background_color='white').generate(comment_words)
We create an instance of WordCloud with specified dimensions and background color and generate the word cloud using the sample text.
Conclusion
In this blog, we’ve explored three essential NLP preprocessing techniques: stopwords removal, bag of words, and word cloud generation. Each technique serves a unique purpose in the text preprocessing pipeline, contributing to the overall effectiveness of NLP tasks. By understanding and implementing these techniques, we can transform raw text data into meaningful insights and powerful features for machine learning models. Happy coding and exploring the world of NLP!
This brings us to the end of this article. I hope you have understood everything clearly. Make sure you practice as much as possible.
If you wish to check out more resources related to Data Science, Machine Learning and Deep learning, you can refer to my Github account.
You can connect with me on LinkedIn — RAVJOT SINGH.
I hope you like my article. From a future perspective, you can try other algorithms or choose different values of parameters to improve the accuracy even further. Please feel free to share your thoughts and ideas.
P.S. Claps and follows are highly appreciated.
Exploring NLP Preprocessing Techniques: Stopwords, Bag of Words, and Word Cloud was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.