













Decoding the AI mind: Anthropic researchers peer inside the “black box”
Anthropic researchers successfully identified millions of concepts within Claude Sonnet, one of their advanced LLMs. Their study peels back the layers of a commercial AI model, in this case, Anthropic‘s own Claude 3 Sonnet, offering intriguing insights into what lies inside its “black box.” AI models are often considered black boxes, meaning you can’t ‘see’ inside them to understand exactly how they work. When you provide an input, the model generates a response, but the reasoning behind its choices isn’t clear. Your input goes in, and the output comes out – and not even AI companies truly understand what happens The post Decoding the AI mind: Anthropic researchers peer inside the “black box” appeared first on DailyAI.

Anthropic researchers successfully identified millions of concepts within Claude Sonnet, one of their advanced LLMs.
Their study peels back the layers of a commercial AI model, in this case, Anthropic‘s own Claude 3 Sonnet, offering intriguing insights into what lies inside its “black box.”
AI models are often considered black boxes, meaning you can’t ‘see’ inside them to understand exactly how they work.
When you provide an input, the model generates a response, but the reasoning behind its choices isn’t clear. Your input goes in, and the output comes out – and not even AI companies truly understand what happens inside.
Neural networks create their own internal representations of information when they map inputs to outputs during data training. The building blocks of this process, called “neuron activations,” are represented by numerical values.
Each concept is distributed across multiple neurons, and each neuron contributes to representing multiple concepts, making it tricky to map concepts directly to individual neurons.
This is broadly analogous to our human brains. Just as our brains process sensory inputs and generate thoughts, behaviors, and memories, the billions, even trillions, of processes behind those functions remain primarily unknown to science.
Anthropic’s study attempts to see inside AI’s black box with a technique called “dictionary learning.”
This involves decomposing complex patterns in an AI model into linear building blocks or “atoms” that make intuitive sense to humans.
Mapping LLMs with Dictionary Learning
In October 2023, Anthropic applied this method to a tiny “toy” language model and found coherent features corresponding to concepts like uppercase text, DNA sequences, surnames in citations, mathematical nouns, or function arguments in Python code.
This latest study scales up the technique to work for today’s larger AI language models, in this case, Anthropic‘s Claude 3 Sonnet.
Here’s a step-by-step of how the study worked:
Identifying patterns with dictionary learning
Anthropic used dictionary learning to analyze neuron activations across various contexts and identify common patterns.
Dictionary learning groups these activations into a smaller set of meaningful “features,” representing higher-level concepts learned by the model.
By identifying these features, researchers can better understand how the model processes and represents information.
Extracting features from the middle layer
The researchers focused on the middle layer of Claude 3.0 Sonnet, which serves as a critical point in the model’s processing pipeline.
Applying dictionary learning to this layer extracts millions of features that capture the model’s internal representations and learned concepts at this stage.
Extracting features from the middle layer allows researchers to examine the model’s understanding of information after it has processed the input before generating the final output.
Discovering diverse and abstract concepts
The extracted features revealed an expansive range of concepts learned by Claude, from concrete entities like cities and people to abstract notions related to scientific fields and programming syntax.
Interestingly, the features were found to be multimodal, responding to both textual and visual inputs, indicating that the model can learn and represent concepts across different modalities.
Additionally, the multilingual features suggest that the model can grasp concepts expressed in various languages.

Analyzing the organization of concepts
To understand how the model organizes and relates different concepts, the researchers analyzed the similarity between features based on their activation patterns.
They discovered that features representing related concepts tended to cluster together. For example, features associated with cities or scientific disciplines exhibited higher similarity to each other than to features representing unrelated concepts.
This suggests that the model’s internal organization of concepts aligns, to some extent, with human intuitions about conceptual relationships.
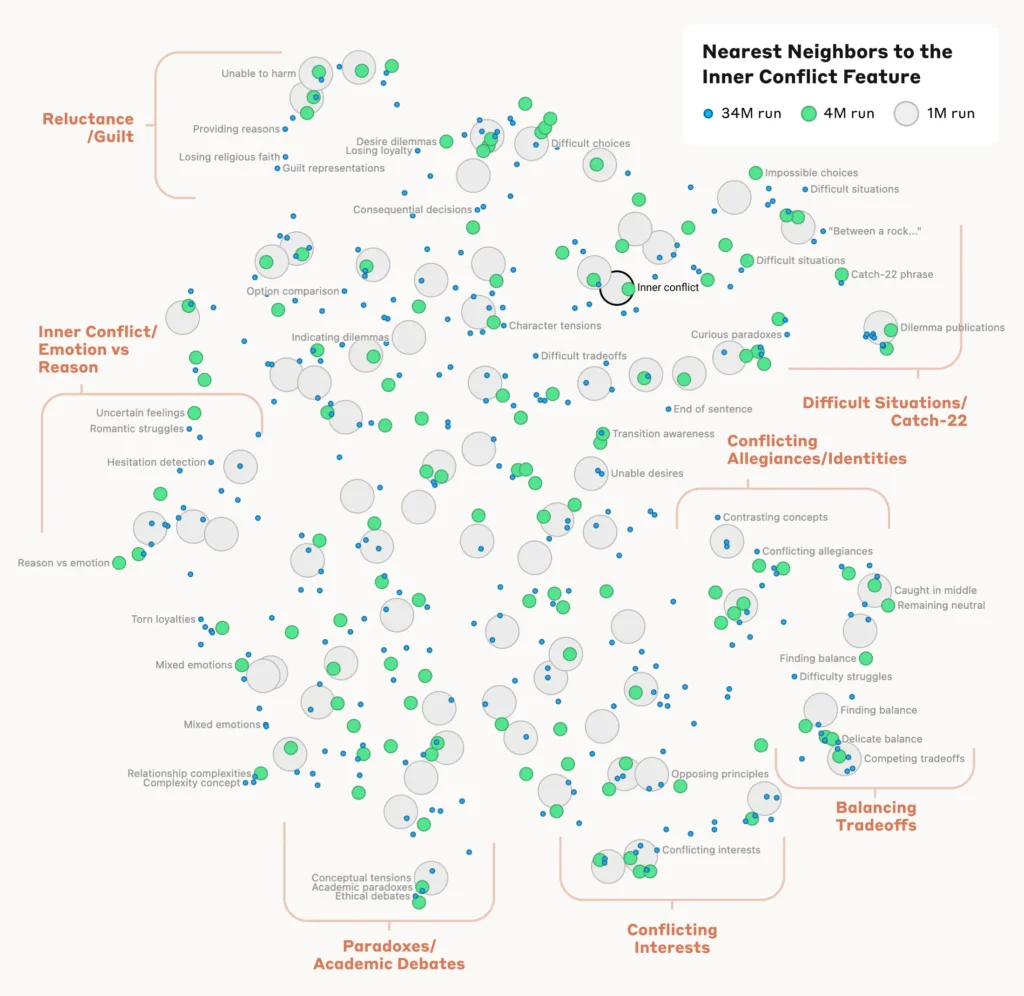
Verifying the features
To confirm that the identified features directly influence the model’s behavior and outputs, the researchers conducted “feature steering” experiments.
This involved selectively amplifying or suppressing the activation of specific features during the model’s processing and observing the impact on its responses.
By manipulating individual features, researchers could establish a direct link between individual features and the model’s behavior. For instance, amplifying a feature related to a specific city caused the model to generate city-biased outputs, even in irrelevant contexts.
Why interpretability is critical for AI safety
Anthropic’s research is fundamentally relevant to AI interpretability and, by extension, safety.
Understanding how LLMs process and represent information helps researchers understand and mitigate risks. It lays the foundation for developing more transparent and explainable AI systems.
As Anthropic explains, “We hope that we and others can use these discoveries to make models safer. For example, it might be possible to use the techniques described here to monitor AI systems for certain dangerous behaviors (such as deceiving the user), to steer them towards desirable outcomes (debiasing), or to remove certain dangerous subject matter entirely.”
Unlocking a greater understanding of AI behavior becomes paramount as they become ubiquitous for critical decision-making processes in fields such as healthcare, finance, and criminal justice. It also helps uncover the root cause of bias, hallucinations, and other unwanted or unpredictable behaviors.
For example, a recent study from the University of Bonn uncovered how graph neural networks (GNNs) used for drug discovery rely heavily on recalling similarities from training data rather than truly learning complex new chemical interactions. This makes it tough to understand how exactly these models determine new drug compounds of interest.
Last year, the UK government negotiated with major tech giants like OpenAI and DeepMind, seeking deeper access and understanding of their AI systems’ internal decision-making processes.
Regulation like the EU’s AI Act will pressure AI companies to be more transparent, though commercial secrets seem sure to remain under lock and key.
Anthropic’s research offers a glimpse of what’s inside the box by ‘mapping’ information across the model.
However, the truth is that these models are so vast that, by Anthropic’s own admission, “We think it’s quite likely that we’re orders of magnitude short, and that if we wanted to get all the features – in all layers! – we would need to use much more compute than the total compute needed to train the underlying models.”
That’s an interesting point – reverse engineering a model is more computationally complex than engineering the model in the first place.
It’s reminiscent of hugely expensive neuroscience projects like the Human Brain Project (HBP), which poured billions into mapping our own human brains only to ultimately fail.
Never underestimate how much lies inside the black box.
The post Decoding the AI mind: Anthropic researchers peer inside the “black box” appeared first on DailyAI.

.jpg)







